
Pumping Code #10 — AWS re:Invent 2025: Swami’s Keynote
The customization revolution: From months to days, from generic to specialized


Dr. Swami Sivasubramanian, VP of Agentic AI at AWS, took the stage on Day 2 of re:Invent with a clear mission: solve the two biggest blockers keeping AI agents stuck in prototype purgatory—model efficiency and production readiness. His message was direct: most agents waste expensive compute on routine tasks, and most organizations lack the tools to customize models without PhD-level expertise.
This wasn’t a research preview showcase. Swami unveiled production-grade capabilities that fundamentally change how teams build, customize, and deploy agents—with real customers already seeing 66-73% accuracy improvements and cutting experimentation cycles from weeks to days.
Let’s unpack what AWS announced and why it matters.
⚡ Tech Pulse
The Efficiency Problem: Why Your Agents Are Burning Money
Sivasubramanian noted that companies typically opt for the largest, most capable models to power their agents, but agents spend significant time on routine tasks that don’t require advanced intelligence. Checking calendars, searching documents, basic data entry—these don’t need frontier models burning compute at premium rates.
The solution? Advanced model customization made accessible. Two major announcements address this head-on.
Reinforcement Fine Tuning in Amazon Bedrock: PhD-Free Customization

Reinforcement Fine Tuning in Amazon Bedrock delivers 66% accuracy gains on average over base models, helping teams get better results with smaller, faster, more cost-effective models. Rather than relying on massive labeled datasets, RFT teaches models through feedback on multiple possible responses—rewarding good behavior, correcting bad decisions.
The workflow is automated end-to-end:
Select your base model (launching with Nova 2 Lite, more coming soon)
Point to your data (invocation logs or uploaded datasets—no labeling required)
Define your reward function (AI-based, rule-based, or ready-to-use templates)
Let Bedrock handle the rest
Phil Mui from Salesforce noted their benchmarking with RFT shows up to 73% improvement over base models in accuracy for their specific business requirements. That’s not marginal improvement—that’s transformative.
Key insight: Fine-tuning is like turning a general assistant into a specialist, like turning a family doctor into a cardiologist who is laser-focused on exactly what you need them to know. A dataset with 10,000 carefully curated agent interactions can outperform millions of generic examples.
SageMaker AI Serverless Customization: Two Paths, One Goal

Amazon SageMaker AI now supports serverless model customization with two experiences: a self-guided path for developers who want control, and an agentic-driven experience where an AI expert guides through the whole process using natural language.
The agentic experience (in preview): Describe your needs in natural language—”I need a model that understands medical terminology better”—and the agent handles synthetic data generation, data quality analysis, training, and evaluation. Zero infrastructure thinking required.
The self-guided experience: Point-and-click interface with full control over techniques including:
Supervised Fine-Tuning
Reinforcement Learning from AI Feedback (RLAIF)
Reinforcement Learning from Verifiable Rewards (RLVR)
Direct Preference Optimization
Both approaches work with Amazon Nova, Llama, Qwen, DeepSeek, and GPT-OSS models, giving teams flexibility to match the right model to their use case.
AgentCore Gets Smarter: Episodic Memory
AWS announced Episodic Memory for AgentCore, a new functionality that gives agents the ability to remember and learn from past experiences, storing and recalling specific interactions as discrete episodes similar to how humans remember particular events.
Think of a booking agent that initially books a 45-minute buffer before your flight, but you miss it due to family obligations. With episodic memory, the next time it books for you, it automatically suggests a longer buffer—learning from experience rather than repeating the same pattern.
The memory system includes:
Short-term memory: Real-time conversation context within a session
Long-term memory: Three built-in strategies
summaryMemoryStrategy: Summarizes conversation sessionsuserPreferenceMemoryStrategy: Learns and stores user preferencessemanticMemoryStrategy: Extracts and stores factual information
Episodic functionality: Captures complete interaction episodes with situation, intent, assessment, and outcomes
Reflections: Background analysis that consolidates across multiple episodes to identify patterns, successful strategies, and lessons learned
Real-world impact: Cox Automotive used AgentCore and Strands to transform back-office processes, reducing tasks that took two days per estimator down to less than thirty minutes per vehicle.
Strands Goes TypeScript + Edge: 5M Downloads and Growing
Strands Agents SDK has reached 5 million downloads, and AWS is expanding its reach with two major additions:
TypeScript Support (in preview): Developers can now build their entire agentic stack in TypeScript using AWS CDK. Full support for type safety, async/await, and modern JavaScript/TypeScript patterns. This opens Strands to one of the world’s most popular programming language communities.
Edge Device Support (GA): Run autonomous AI agents on small devices—automotive systems, gaming consoles, robotics platforms. Agents can now deliver intelligent services in the real world, not just cloud environments.
Checkpointless Training: The GPU-Efficiency Revolution
Traditional model training on large clusters faces a brutal problem: hardware failures are inevitable, and checkpoint-based recovery leaves multi-million-dollar GPU clusters idle for hours. Checkpointless training on SageMaker HyperPod eliminates disruptive checkpoint-restart cycles, reducing recovery time from hours to minutes.
How it works:
Continuous state preservation across the entire training compute cluster
Peer-to-peer recovery: When faults occur, the system automatically swaps out faulty hardware and transfers model state from nearby healthy accelerators
Zero manual intervention: Automatic detection and recovery even with thousands of accelerators
95% cluster efficiency: Maintain forward training momentum despite failures
The latest Amazon Nova models were trained using checkpointless training on tens of thousands of accelerators. This isn’t experimental—it’s battle-tested at massive scale.
Four core components work together:
Collective communications initialization optimizations
Memory-mapped data loading with caching
In-process recovery
Checkpointless peer-to-peer state replication
Elastic Training (also announced): Training jobs automatically scale up to utilize available accelerators and gracefully contract when resources are needed elsewhere—maximizing cluster utilization without manual intervention.
Neurosymbolic AI: The Reasoning Foundation
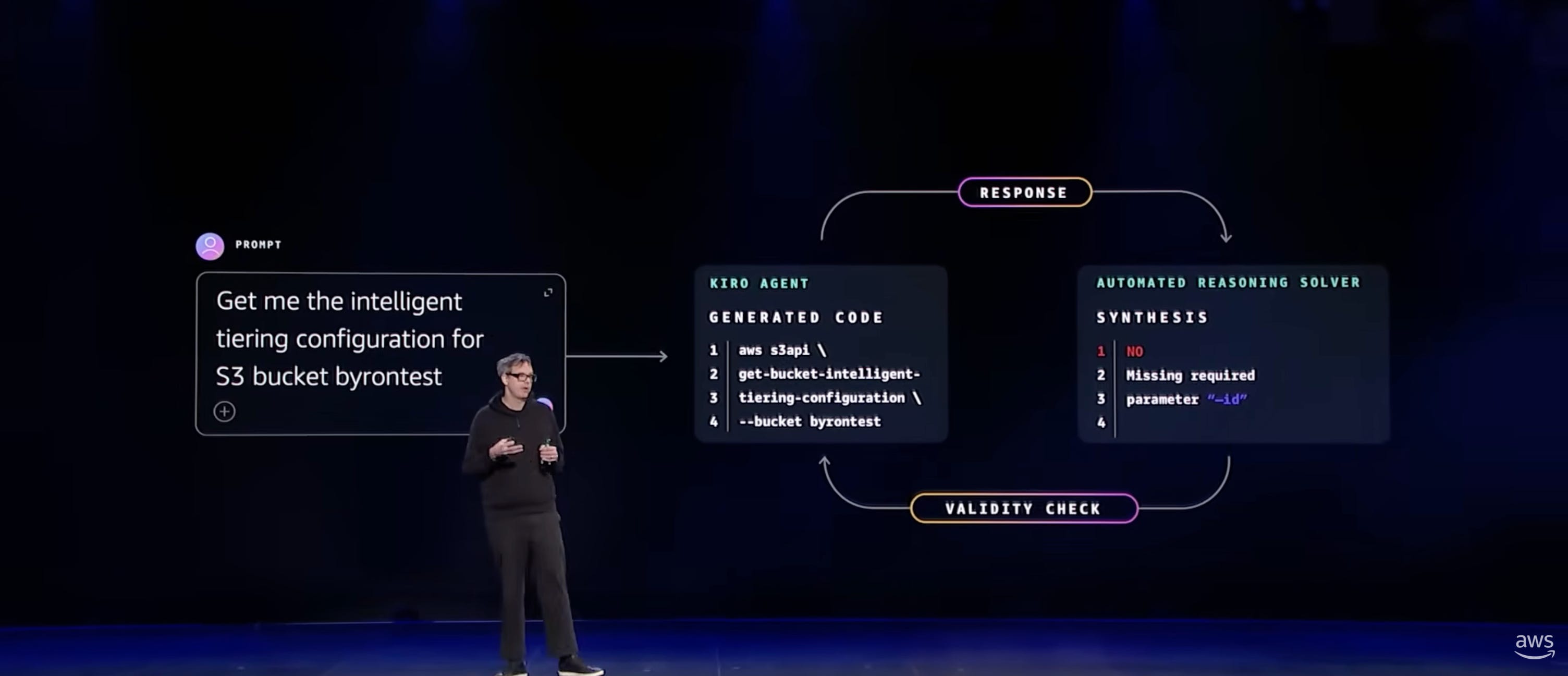
Byron Cook, AWS’s expert in automated reasoning, introduced the company’s approach to trustworthy agents: combining automated reasoning with LLMs. Neurosymbolic AI combines automated reasoning with LLMs for trustworthy agents, using mathematical logic to reason about all possible executions of a computer program.
The goal: specify constraints on agents at the outset, giving them freedom to operate while defining safe boundaries—then get assurance they’ll follow those constraints even when subtle or complex.
💻 Code Gym
1. Reinforcement Fine Tuning in Amazon Bedrock
What it enables: Customize models with 66% average accuracy gains using reward functions instead of massive labeled datasets. Works with Nova 2 Lite at launch.
Official guide: Improve model accuracy with reinforcement fine-tuning in Amazon Bedrock
What’s covered:
Creating RFT jobs through console or API
Setting up reward functions (rule-based or AI-based judges)
Using invocation logs or uploaded datasets as training data
Deploying fine-tuned models with on-demand inference
Interactive demo walkthrough
Key insight: The blog shows the complete workflow from job creation through deployment, including how to use the Bedrock console’s visual interface and the underlying API calls.
2. Serverless Model Customization in Amazon SageMaker AI
What it enables: Customize models in days instead of months with zero infrastructure management. Two paths: agentic (AI-guided) or self-guided (full control).
Official guide: New serverless customization in Amazon SageMaker AI accelerates model fine-tuning
What’s covered:
Both agentic and self-guided customization workflows
Using techniques like RLVR, RLAIF, SFT, and DPO
Working with Nova, Llama, Qwen, DeepSeek, and GPT-OSS models
Automatic compute provisioning and scaling
MLflow integration for experiment tracking
Deploying to both SageMaker and Bedrock endpoints
Key insight: The agentic experience lets you describe needs in natural language and handles synthetic data generation, quality analysis, training, and evaluation automatically.
3. AgentCore Memory with Strands Agents
What it enables: Give agents the ability to remember conversations, learn user preferences, and recall past episodes to improve decision-making over time.
Official documentation: Add memory to your Amazon Bedrock AgentCore agent
Integration guide: Strands Agents SDK - AgentCore Memory
What’s covered:
Creating memory resources with built-in strategies (summary, user preference, semantic, episodic)
Integrating AgentCore Memory with Strands session managers
Configuring short-term and long-term memory
Setting up episodic memory for experience-based learning
Using namespaces for memory organization
Key insight: The Strands integration makes memory management automatic—agents store and retrieve context without explicit memory management code in your application logic.
4. Checkpointless Training on Amazon SageMaker HyperPod
What it enables: Recover from training faults in minutes instead of hours with automatic peer-to-peer state recovery. Achieve 95% cluster efficiency even with thousands of accelerators.
Official guide: Introducing checkpointless and elastic training on Amazon SageMaker HyperPod
GitHub repository: aws/sagemaker-hyperpod-checkpointless-training
What’s covered:
Four core components: communication optimization, memory-mapped data loading, in-process recovery, peer-to-peer state replication
Integration with PyTorch Lightning and NVIDIA NeMo
Configuration through HyperPod recipes and Kubernetes manifests
Elastic training for automatic scaling based on resource availability
Real-world usage at scale (Nova models trained on tens of thousands of accelerators)
Key insight: The GitHub repo includes production-ready recipes for popular models like GPT-OSS and LLaMA, making it easy to enable checkpointless training with minimal code changes.
5. Strands Agents TypeScript Support
What it enables: Build full-stack agentic applications in TypeScript with the same powerful abstractions available in Python. Now with 5M+ downloads.
Official documentation: Strands Agents GitHub
What’s covered:
TypeScript SDK with full type safety and async/await support
Integration with AWS CDK for infrastructure-as-code
Edge device support for automotive, gaming, and robotics
Model Context Protocol (MCP) server integration
Tool definition and orchestration patterns
Key insight: TypeScript support brings Strands to the massive JavaScript/TypeScript developer community while maintaining the same agent development patterns proven in the Python SDK.
🚀 What You Should Do This Week
If you’re building agents:
Test RFT for specialized tasks: Take your highest-value agent use case and create an RFT job with your invocation logs. The 66-73% accuracy improvements are real—start with Nova 2 Lite and measure the difference.
Enable AgentCore Memory: Add episodic memory to agents that need to learn from experience. Customer support, booking systems, and any workflow where patterns matter should have this enabled.
Prototype with Strands TypeScript: If your team uses TypeScript, build an agent end-to-end with the new SDK. The unified AWS CDK experience makes infrastructure-as-code natural.
If you’re training models:
Migrate to checkpointless training: If you’re running multi-day training jobs on large clusters, the recovery time improvements alone justify migration. Test with the HyperPod recipes on GitHub.
Try serverless customization in SageMaker: For your next fine-tuning project, use the agentic experience. Let AWS handle infrastructure while you focus on data quality and evaluation.
If you’re scaling AI infrastructure:
Evaluate cost savings from specialized models: Measure the inference cost difference between using GPT-4 class models for everything vs. using RFT-tuned Nova 2 Lite for routine tasks. The economics are compelling.
Implement elastic training: If you have fluctuating workload patterns, enable elastic training to automatically scale training jobs with cluster availability.
Architecture Decision
The Production Agent Stack for 2025: Strands (TypeScript) for rapid development → AgentCore Memory for learning → RFT-customized Nova models for efficiency → AgentCore Policy for governance → AgentCore Evaluations for quality monitoring. Train custom models with SageMaker serverless customization, optimize at scale with checkpointless training on HyperPod.
This isn’t a research stack—it’s production infrastructure designed for teams that need to ship agents that actually work, at costs that actually scale.
The Bottom Line
Swami’s keynote addressed the two core problems blocking agent adoption: efficiency (agents burning money on routine tasks with oversized models) and accessibility (advanced customization requiring PhD-level expertise).
The solutions shipped:
66-73% accuracy gains from RFT without massive datasets
Weeks-to-days reduction in customization cycles with serverless SageMaker
Hours-to-minutes recovery from training faults with checkpointless training
Real learning through episodic memory that improves agent decisions over time
Customer proof points validate the approach: Cox Automotive reducing two-day processes to 30 minutes, Salesforce seeing 73% accuracy improvements, Collinear AI cutting experimentation from weeks to days.
The most important shift? Democratizing advanced techniques. You don’t need a team of ML PhDs to build production-grade agents anymore. The infrastructure exists, it’s managed, and it works.
Read the full technical docs and start building:
🧠 Keep building. Keep shipping. Keep iterating.
— Puria